早期基于深度学习的2D人体姿态估计采用直接回归的关键点的坐标(DeepPose),但是这种方法很难收敛,因为在训练中,很难使得模型的输出固定在一个值。将heatmap的概念引入到姿态估计中,使得基于深度学习的2D人体姿态估计算法取得了较大的发展,这里所说的heatmap指的是以每个关键点的位置为中心,加一个高斯核得到的heatmap,这样可以大大降低模型优化的难度。主要分为top down和bottom up两种模式。
Top down是将姿态估计分为两个大的阶段,第一个阶段使用目标检测算法检测人体位置,然后将图像中的人体部分的进行裁剪,再对这一部分进行姿态估计,这一种方法很容易从单人姿态估计推广到多人姿态估计,只需要训练一种对单人进行姿态估计的算法就可以了。但是这种算法受前一阶段中的目标检测算法影响较大,同时这两个算法是独立进行,对于目标检测中提取到的特征,在后续的姿态估计中根本没有用到,同时在进行姿态估计时,姿态估计算法也都针对每个人进行单独推理,这对硬件的要求较高,很难实用。
Bottom up是取消了top down中对姿态估计的目标检测阶段,直接对图像中的所有人物的关键点的位置进行回归,然后再对这些位置进行组合,将这些关键点组合成一个个的人。这一种方法很明显就是直接针对多人的姿态估计来做的,可以使得模型在一次前向推理中获得图像中所有人的关键点信息,在速度上要明显优于top down的方式。
Top down
1. CPM(Convolutional Pose Machines 2016)
这篇文章提出一个多阶段的网络用于人体姿态估计,如下图所示,通过增加阶段来提升网络感受野,进而来提升姿态估计的精度。
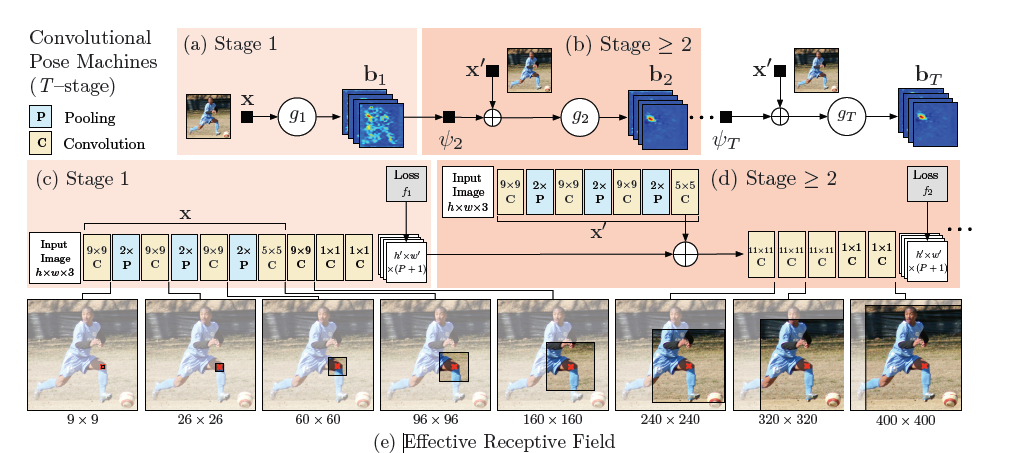
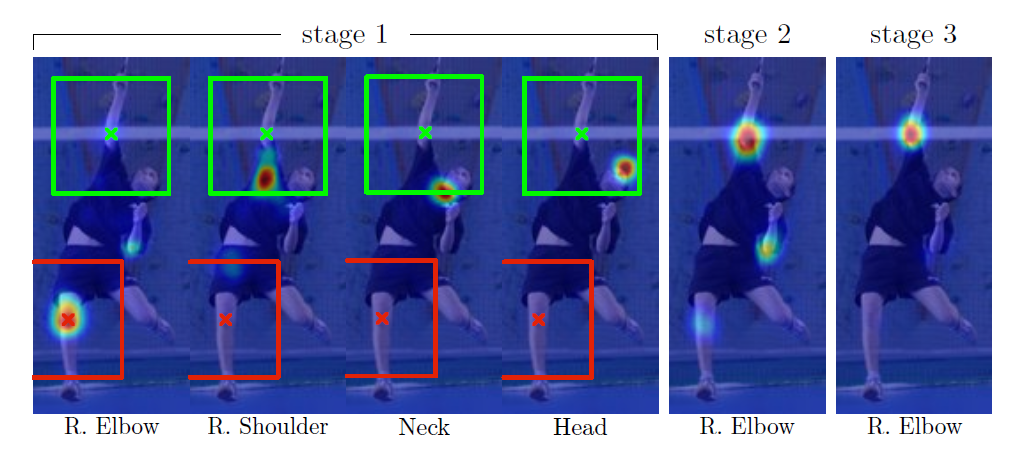
该方法采用局部定位与全局定位相结合的方法对人体姿态进行估计,如下图所示局部定位可以准确定位到简单关键点如头部,脖子,肩部等位置,但是对于手肘处却定位错,又经历两个阶段后,通过利用全局信息手肘处的关键点才得到了精确的定位,简单关键点就是指其局部特征比较明显,使用局部信息就可以准确定位到这些关键点,然后有了这些简单关键点的信息在利用这些位置信息重新定位困难的关键点,最终实现对人体姿态的估计;由于是多阶段的网络,网络层数足够多,引入了intermediate supervision对网络进行优化,这样解决了梯度消失的问题。
评价指标为PCKh@0.5,在MPII数据集上达到87.95%
2. Hourglass(Stacked Hourglass Networks for Human Pose Estimation 2016)
这篇文章也是提出了一个多阶段的模型,设计了一个Hourglass模块,因为对图像先进行下采样,在进行上采样恢复到原来的分辨率,这样的操作形似沙漏,因此称为Hourglass模块,其网络结构如下图。该网络通过对图像进行反复的上下采样挖掘图像特征,同时也使用了intermediate supervision对模型进行优化,最终将这些特征融合成关键点heatmap来估计关键点的位置。
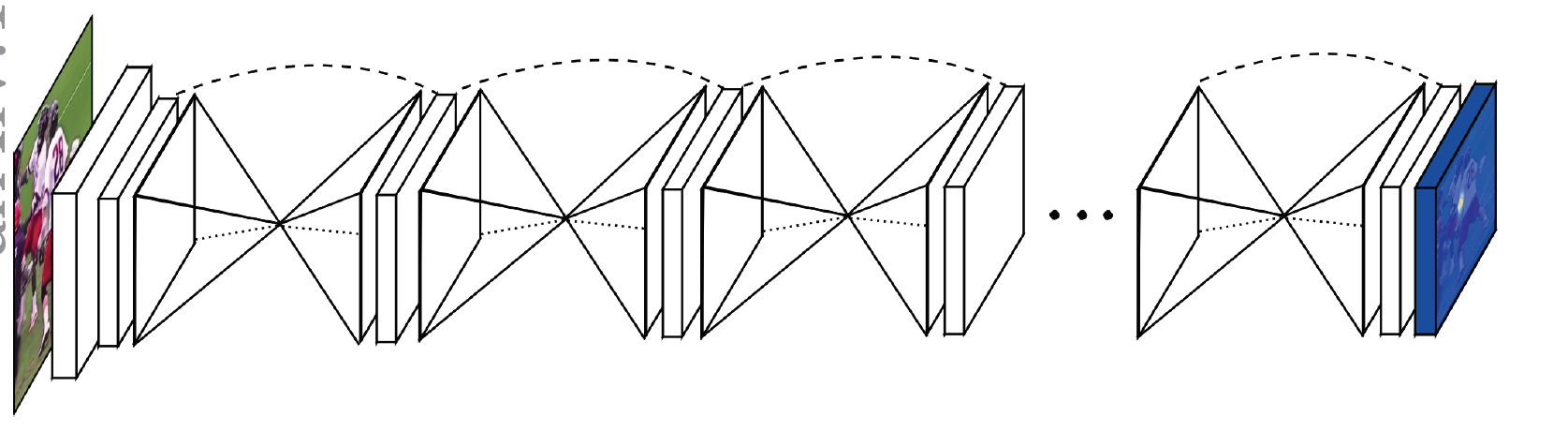
在MPII数据集上达到90.9%
3. CPN(Cascaded Pyramid Network for Multi-Person Pose Estimation 2018)
这篇文章与CPM的思路类似,首先将简单关键点定位出来,再利用这些简单关键点的语义信息定位出复杂关键点。整个网络结构分为GlobalNet与RefineNet,在GlobalNet中提取图像金字塔特征,再将这些特征融合得到初步的heatmap;在RefineNet中对使用多个尺度和多个的特征信息来定位关键点。
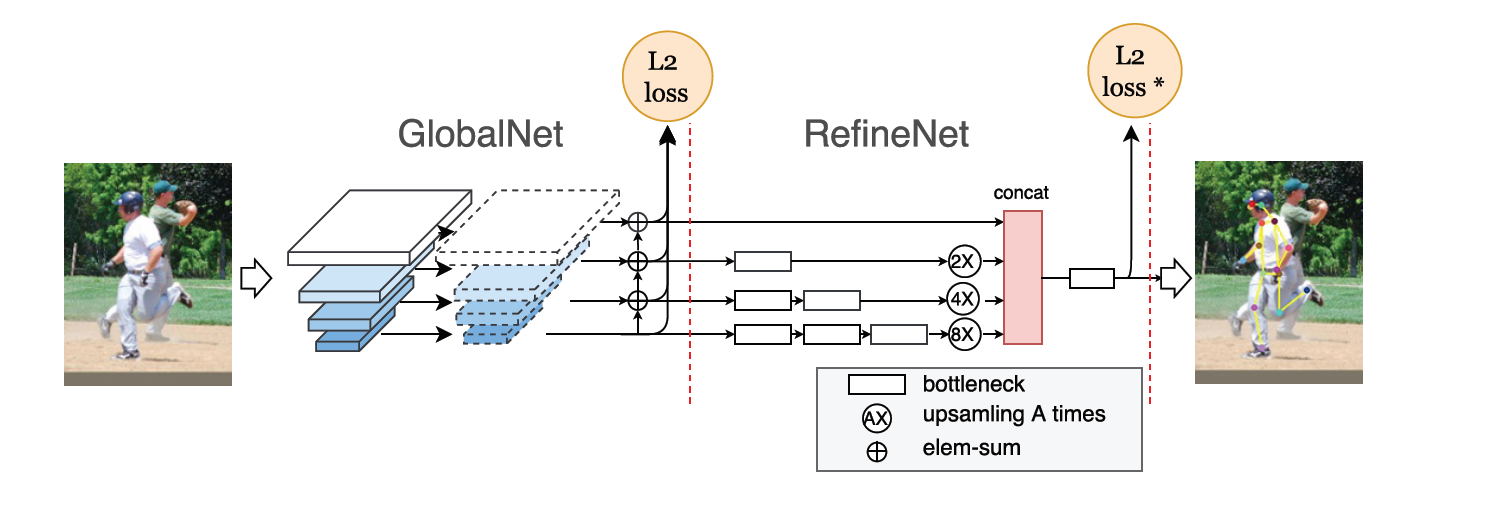
评价指标为在OKS上计算AP,在COCO test-dev数据集上mAP达到72.1(with ensembled model 73.0),AP@0.5达到91.4(91.7)
4. HRNet(Deep High-Resolution Representation Learning for Human Pose Estimation 2019)
之前关于Top down网络的结构大都是先下采样,再上采样,最终得到的HR特征时从低分辨率特征中得到的,这其中不可避免的就会丢失信息,本篇文章从这个角度出发设计了如下图所示的结构,通过上采样来对HR特征进行融合从而提升网络的精度。
评价指标为在OKS上计算AP,在COCO test-dev数据集上mAP达到75.5(+extra data 77.0),AP@0.5达到92.4(+extra data 92.7)
5.MSPN(Rethinking on Multi-Stage Networks for Human Pose Estimation 2019)
这个工作从多阶段网络出发设计网络,针对当前多阶段网络的一些问题进行了进一步的研究。主要有以下几个方面
- 单阶段模块
- intermediate supervision
- 跨阶段特征收集
从下图的结构可以看出,该网络结构与CPN的GlobalNet比较相似,但与它不同的是在此基础上进行了一些改进,首先是对单阶段的模块进行了改进,之前的单阶段模块对于高分辨率与低分辨率特征都采用同样的通道数,但是对于低分辨率特征拥有更多的语义信息,因此在通道数上应该增加;其次在中间监督上,采用了从粗到细的方式,前期采用较大的高斯核构建ground truth heatmap,在后面的阶段中使用较小的高斯核;最后增加了跨阶段的跳线连接,对于不同阶段的特征进行了融合。
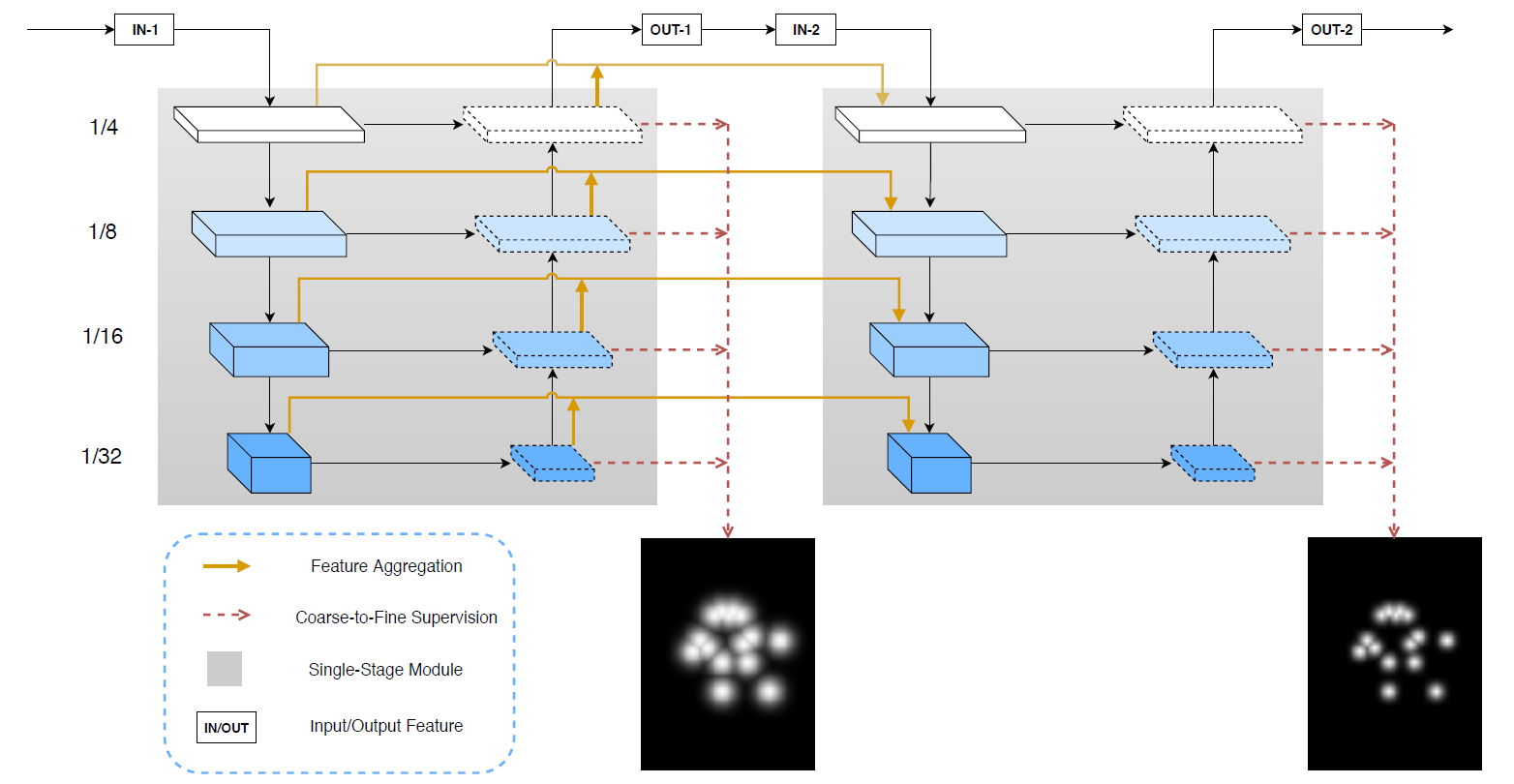
评价指标为在OKS上计算AP,在COCO test-dev数据集mAP达到77.1(with ensemble model 78.1),AP@0.5达到93.8(with ensemble model 94.1)
Bottom up
1. OpenPose(OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields 2016)
这篇文章提出了局部亲和力场(part affinity fields, PAF),根据PAF可以得到两个节点是否归属于同一个人,PAF的示意图如下图所示。
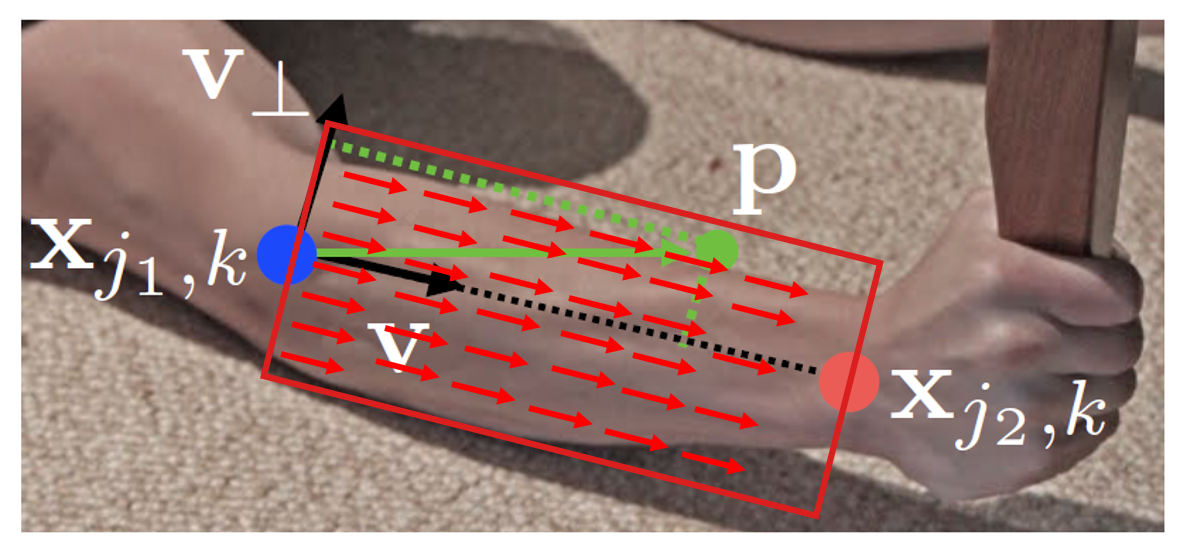
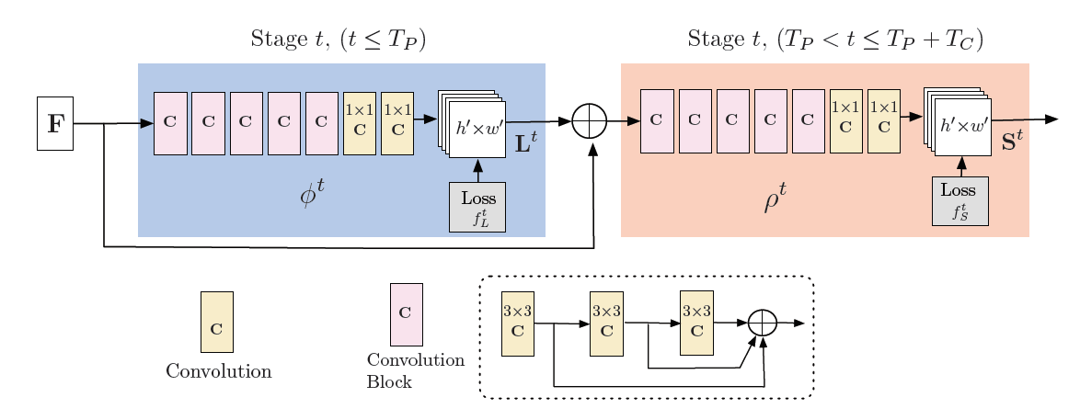
本文采用一个多阶段的模型来学习PAF与heatmap,如下图所示,前\(T_p\)个阶段学习PAF,在后续阶段中学习关键点的heatmap。
最后对PAF使用匈牙利算法将关键点组合在一起得到最终的姿态估计结果。
评价指标为在PCKh上计算AP,在MPII数据集上mAP达到了75.6,在COCO test-dev数据集上mAP达到了64.2,AP@0.5达到了86.2
2. Associative Embedding(Associative Embedding: End-to-End Learning for Joint Detection and Grouping 2017)
本文针对多人姿态估计任务提出了组合一个组合关键点的方法,通过对每个位置进行分类,但这个分类不是直接对这个位置打上一个ground truth的label,相反根本没有ground truth,因为根本不可能预先知道图像中有几个人,因此不能预先设定通道数,同时每幅图像中每个人都是不同的,也没有办法给一个人一个固定的label。在这篇文章中,针对这个问题,虽然不能保证输出的类别的具体值,但是要保证同一个类别的值要相近,同时不同类别之间的值要区别大。本人将associative embedding嵌入到Hourglass中实现多人姿态估计。
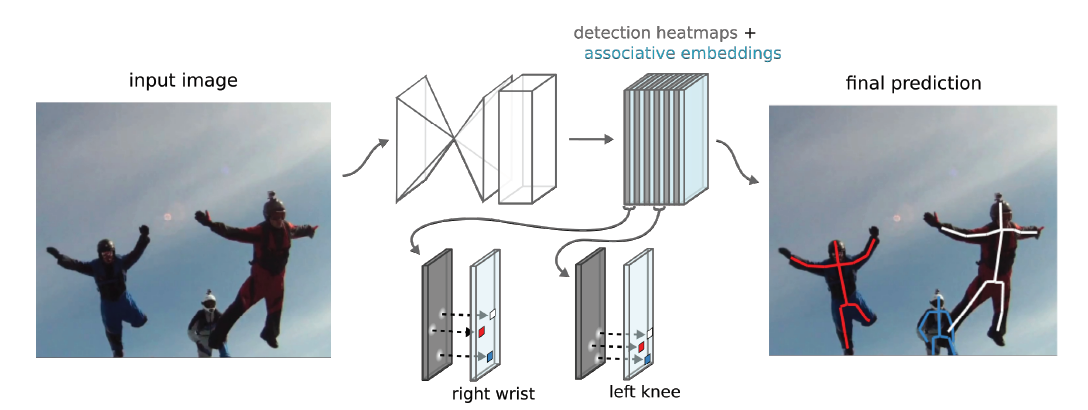
评价指标为在OKS上计算AP,在MPII数据集上达到77.5,在COCO test-dev上达到65.5
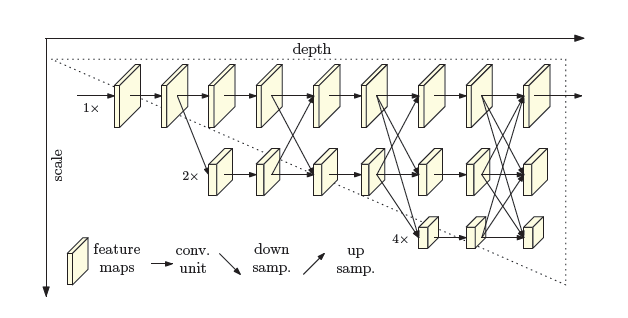
3. HigherHRNet(HigherHRNet: Scale-Aware Representation Learning forBottom-Up Human Pose Estimation 2020)
本针对当人在一幅图像中较小时当前的算法很难对其进行姿态估计的问题,进行了一些改进。如下图所示,该方法以HRNet为backbone,以原来的\(1/4\)分辨率的特征处理大一些的人,然后使用一个反卷积层将特征的分辨率提升到\(1/2\)来处理小一些的人,同时分别针对这两种分辨率构建ground truth heatmap进行监督。使用associative embedding处理关键点的归属问题。
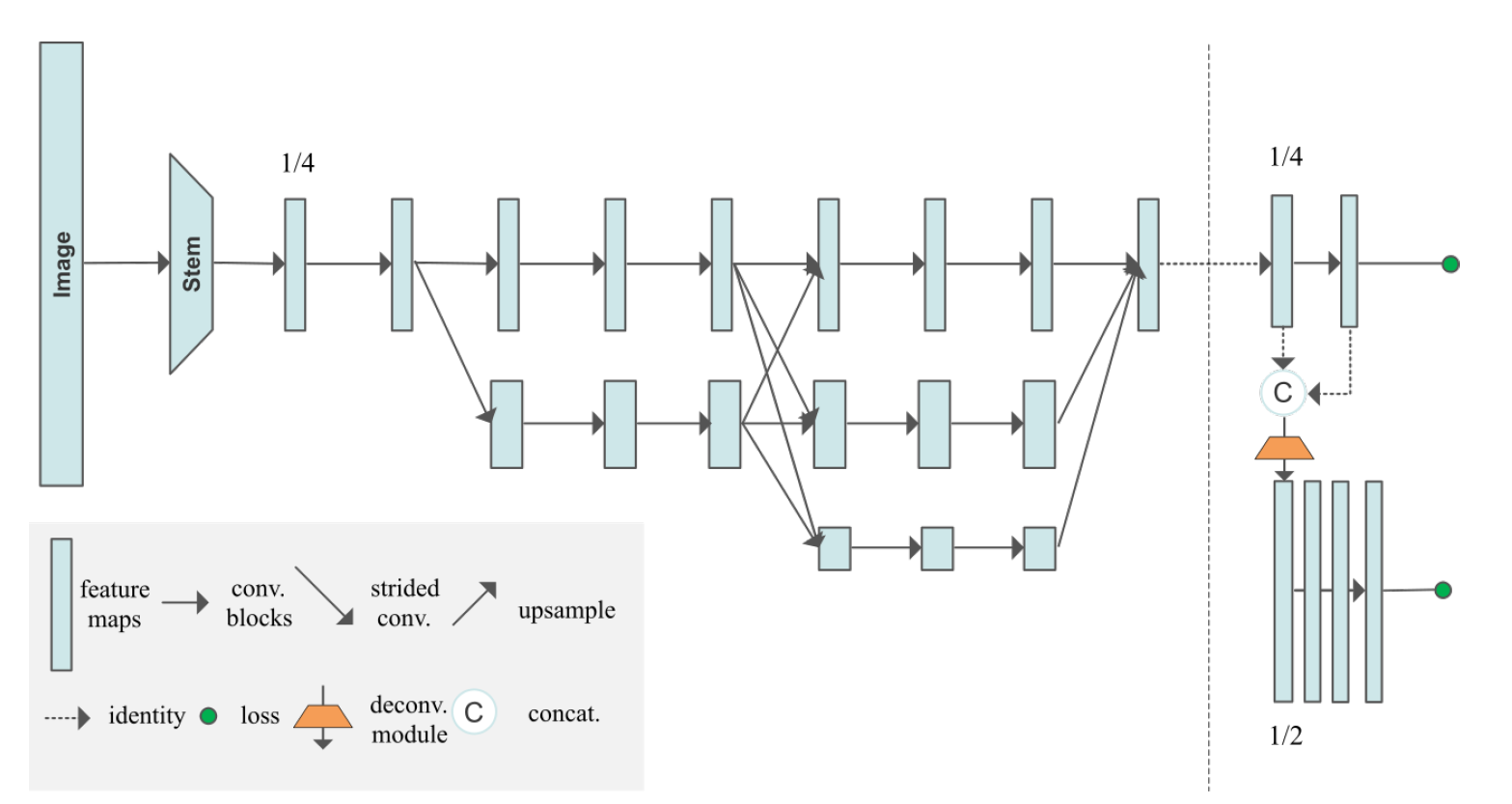
评价指标为在OKS上计算AP,在COCO 2017 test-dev上mAP达到68.4(with multi-scale test 70.5)